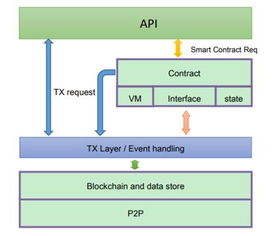
英特爾宣布推出專為高性能計算(HPC)和人工智能(AI)優化的新型8位浮點處理格式——FP8。這一創新旨在顯著提升數據處理效率和存儲支持能力,為日益復雜的AI模型和高性能計算工作負載提供關鍵的技術支撐。
隨著AI模型規模不斷擴大,對計算精度、內存帶寬和能效的要求也日益嚴苛。傳統的16位半精度(FP16)或32位單精度(FP32)浮點格式雖然能保證較高的數值精度,但在處理大規模數據時,往往面臨存儲空間占用大、數據傳輸延遲高、能耗較高等挑戰。英特爾的FP8格式應運而生,它通過將浮點數壓縮至8位,在保持足夠精度的前提下,大幅減少了數據存儲空間和內存帶寬需求。
從技術角度看,FP8格式平衡了數值范圍和精度。它通常支持兩種子格式:一種側重動態范圍(如E5M2,即5位指數、2位尾數),適用于需要較大數值范圍的場景;另一種側重精度(如E4M3,即4位指數、3位尾數),更適合對精度要求較高的計算。這種靈活性使得FP8能夠根據不同的AI訓練和推理任務進行優化選擇,從而在模型準確性和計算效率之間取得最佳平衡。
英特爾此次推出FP8格式,并非孤立行動,而是其全面AI與HPC戰略的重要組成部分。該格式將與其硬件平臺(如至強可擴展處理器、GPU加速器)和軟件棧(如oneAPI工具包)深度集成,提供端到端的支持。對于開發者而言,這意味著他們可以更輕松地將現有模型遷移至FP8,利用更小的數據位寬實現更快的訓練速度和更低的推理延遲,同時降低數據中心的總擁有成本(TCO)。
在數據處理方面,FP8能夠加速矩陣乘法和卷積等核心AI運算,這對于深度學習中的前向傳播和反向傳播至關重要。在存儲支持上,數據位寬的減半直接轉化為模型和中間數據存儲空間的節省,使得在有限的內存容量下能夠部署更大或更多的模型,特別有利于邊緣計算和移動設備上的AI應用。
行業分析認為,FP8格式的推出正值AI計算從“粗放式”增長轉向“精細化”優化的關鍵節點。隨著OpenAI、谷歌等機構發布的模型參數達到萬億級別,對高效數值格式的需求愈發迫切。英特爾此舉也與英偉達、AMD等競爭對手在低精度計算領域的布局形成呼應,共同推動著行業向更高效的計算范式演進。
FP8格式有望在大型語言模型(LLM)、推薦系統、科學模擬等領域得到廣泛應用。英特爾計劃通過持續的軟件優化和生態系統合作,推動FP8成為AI與HPC社區的新標準之一。廣泛采用仍需解決工具鏈支持、算法適應性以及不同硬件平臺間的兼容性等挑戰。
英特爾FP8浮點格式的推出,標志著其在高效能計算領域又邁出了堅實一步。通過縮小數據位寬而不犧牲關鍵性能,FP8將為下一代AI創新和復雜科學計算提供更強的數據處理與存儲支持,助力各行業在數字化浪潮中挖掘更深層的價值。