隨著物聯網、工業互聯網和邊緣計算的快速發展,智能數據采集終端作為連接物理世界與數字世界的神經末梢,其重要性日益凸顯。海量、異構、實時的終端數據若未經有效處理與分析,其價值將大打折扣。因此,一套功能強大、高效穩定的數據處理與分析軟件,以及與之配套的數據處理與存儲支持服務,構成了智能數據采集系統價值釋放的核心引擎。
一、智能數據采集終端數據處理與分析軟件的核心實現
智能數據采集終端的數據處理與分析軟件通常采用分層架構設計,以確保靈活性、可擴展性和易維護性。其核心實現主要包括以下幾個層面:
- 數據接入與預處理層:
- 多協議適配:軟件需支持Modbus、OPC UA、MQTT、HTTP等多種工業與物聯網通信協議,實現與各類傳感器、PLC、智能儀表的無縫對接。
- 數據清洗與校驗:對采集到的原始數據進行去噪、過濾異常值、填補缺失值、格式標準化等操作,確保數據質量。
- 邊緣計算與輕量級分析:在終端或近終端側執行初步的數據聚合(如求和、平均)、事件檢測、閾值報警等,減輕云端壓力并實現快速響應。
- 核心數據處理與分析引擎:
- 流批一體處理:集成流處理(如Apache Flink, Spark Streaming)和批處理能力,既能對實時數據流進行連續分析,也能對歷史數據進行深度挖掘。
- 內置分析算法庫:提供豐富的分析模型,包括統計分析、趨勢預測、關聯分析、聚類分類以及基于機器學習的故障診斷、能效優化等高級分析功能。
- 可視化規則引擎:允許用戶通過圖形化界面或腳本自定義數據處理邏輯、報警規則和業務工作流,降低開發門檻。
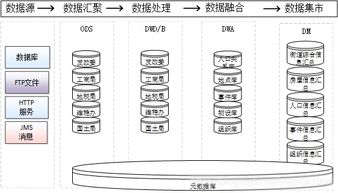
- 數據存儲與管理層:
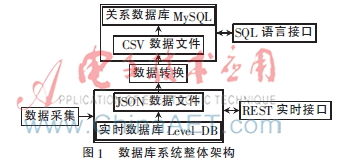
- 多模數據庫支持:根據數據特性選用不同的存儲方案,如時序數據庫(InfluxDB, TDengine)用于高效存儲時間序列數據,關系型數據庫(PostgreSQL)存儲元數據和業務關系,NoSQL數據庫(MongoDB)存儲非結構化或半結構化數據。
- 數據分區與生命周期管理:自動對數據進行熱、溫、冷分層存儲,制定歸檔與清理策略,優化存儲成本與訪問性能。
- 應用與可視化層:
- 多維數據看板:提供可拖拽、可配置的儀表盤,直觀展示關鍵績效指標(KPI)、實時狀態、歷史趨勢和報警信息。
- 報表與報告自動生成:支持定時或觸發式生成標準化分析報告,并支持導出。
- API接口開放:通過RESTful API或WebSocket等方式,將處理后的數據和分析結果安全地提供給第三方業務系統(如ERP、MES)進行集成與應用。
二、數據處理與存儲支持服務的關鍵構成
為確保上述軟件平臺能夠持續、穩定、安全地運行,并提供卓越的數據服務能力,必須構建一套完整的支持服務體系:
- 高性能計算與存儲資源服務:
- 提供可彈性伸縮的云計算、邊緣計算節點或裸金屬服務器資源,滿足數據處理對算力的爆發性需求。
- 提供高IOPS、低延遲的塊存儲、文件存儲及對象存儲服務,保障海量數據寫入與讀取的性能。
- 數據管道與集成服務:
- 提供托管的、可視化的數據集成工具,簡化從終端到數據中心、從數據中心到各類分析應用之間的數據流動配置與管理。
- 支持數據同步、遷移和備份服務,確保數據的一致性與可用性。
- 數據治理與安全服務:
- 元數據管理:建立統一的數據目錄,清晰定義數據來源、格式、含義和血緣關系。
- 訪問控制與審計:實施基于角色(RBAC)或屬性(ABAC)的精細權限控制,對所有數據訪問操作進行完整日志記錄與審計。
- 數據加密:對傳輸中(TLS/SSL)和靜態存儲的數據進行加密,保障數據隱私與合規性(如GDPR、等保2.0)。
- 運維監控與高可用服務:
- 全鏈路監控:對數據采集、傳輸、處理、存儲各個環節的性能指標(如延遲、吞吐量、錯誤率)進行實時監控與告警。
- 容災與備份:提供跨可用區、跨地域的數據冗余備份與業務容災方案,確保服務連續性和數據可靠性。
- 專業技術支持:提供7x24小時的技術支持、系統健康檢查、性能優化咨詢及應急響應服務。
三、
智能數據采集終端的數據處理與分析軟件及其支持服務的實現,是一個將原始數據轉化為智慧洞察的系統性工程。軟件本身通過先進的分層架構和算法模型,解決了“如何加工數據”的問題;而配套的數據處理與存儲支持服務,則從資源、集成、安全和運維層面,解決了“如何讓數據處理持續、穩定、安全地運行”的問題。二者相輔相成,共同構成了企業數據驅動決策的堅實數字基座,為智能制造、智慧能源、智慧城市等領域的數字化轉型與智能化升級提供了關鍵動力。隨著人工智能與大數據技術的進一步融合,該領域將朝著更加自動化、智能化和服務化的方向持續演進。